 AI EBISU
AI EBISU 

LM Arenaとは?AIモデル評価の新しいプラットフォーム
世界中のユーザーが参加するAI格闘技場
ChatGPT、Grok、Gemini…日々様々なAIが登場し、どれがいいのかわからない。そんなときはLM Arenaを見れば疑問が解決するかもしれません。LM Arenaは、世界中のユーザー投票によってAIモデルの性能を評価するウェブサイトです。
従来の企業内テストや学術研究とは異なり、実際にAIを利用する一般ユーザーの視点で各モデルの実力を測定できます。
カリフォルニア大学バークレー校のLMSYSチームが開発した例えば、ChatGPTやGemini、Claudeなどの主要AIモデルが日々バトルを繰り広げています。
ユーザー参加型の評価により、理論値ではなく実用性に基づいた真のAI性能ランキングが形成されるのが最大の特徴です。

従来のベンチマーク評価との決定的な違い
LM Arenaは投票システムによる人間の感覚と判断を重視した評価手法を採用しています。
既存のMMLUやHELMといったベンチマークでは測定困難な「自然さ」「使いやすさ」「創造性」といった要素を正確に評価可能です。
例えば、文章の論理構成や対話の流れ、ユーモアのセンスなど、数値では表現できない微妙なニュアンスまで捉えることができます。
この結果、実際の業務や日常利用において本当に役立つAIモデルを特定できるため、AI選択の精度が格段に向上します。
| 評価方法 | LM Arena | 従来のベンチマーク |
|---|---|---|
| 評価対象 | オープンエンドな対話 | タスク固有のクローズド問題 |
| 指標 | 投票によるElo | 正答率など |
| 強み | 実用的な体感を反映 | 客観性・再現性 |
| 弱み | 好みの偏りが入る | 実務での使い勝手を拾いづらい |
匿名・ブラインドテストで公平な評価を実現
LM Arenaの評価プロセスでは、どのAIモデルが回答しているかを事前に明かさない完全匿名システムを採用しています。例えば、プロプトを入力後、2つのAIモデルがそれぞれの生成結果を提示しますが、どのAIモデルがどちらを作成したかは明かされません。
そのため、ユーザーは企業名やモデル名による先入観を排除した状態で、純粋に回答内容のみに基づいて判断を下すことになります。
投票完了後に初めてモデル名が公開されるため、ブランド力や知名度に左右されない客観的な評価が実現します。
この仕組みにより、新興企業の優秀なAIモデルや、知名度の低いオープンソースモデルも公平な評価を受けられる環境が整っています。
LM Arenaの基本的な使い方【初心者向け完全ガイド】
サイトアクセスから評価開始までの手順
LM Arenaの利用開始は極めてシンプルで、アカウント登録不要でブラウザからすぐに開始できます。
公式サイト(https://lmarena.ai/)にアクセスし、トップページの「Chat」ボタンをクリックするだけで評価画面に移行します。
初回アクセス時には情報の取り扱いに関する同意確認が表示されるため、「Agree」を選択して進んでください。
画面上部に表示される利用規約を確認後、下部のテキスト入力エリアから質問や指示を入力する準備が整います。
Chat機能でAIモデル同士を対戦させる方法
Chat機能では、画面下部の入力フィールドに任意の質問やタスクを入力することで、2つの異なるAIモデルから同時に回答を得ることができます。
「マーケティング戦略を3つ提案してください」や「Pythonでソートアルゴリズムを実装してください」など、日本語・英語問わず様々な内容で試すことが可能です。
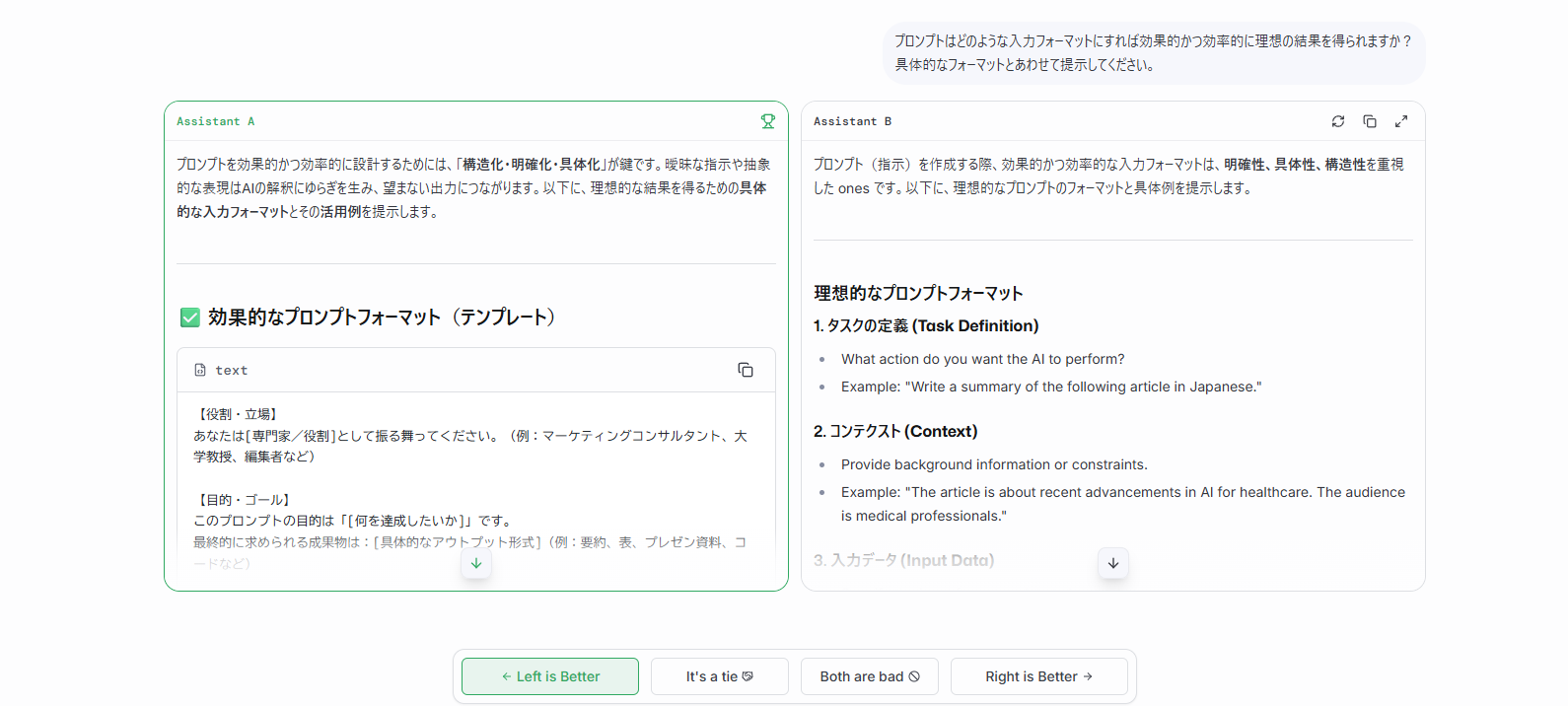
送信ボタンを押すと、「アシスタントA」と「アシスタントB」として匿名化された2つのモデルが並列で回答を生成します。
回答生成には数秒から数十秒程度かかるため、完了まで画面を閉じずに待機してください。
投票・評価の具体的なやり方と注意点
2つの回答が表示されたら、内容を比較検討して優劣を判定します。
画面下部に表示される「Left is Better(左の勝ち)」「It’s a Tie(引き分け)」「Both are bad(両方微妙)」「Right is Better(右の勝ち)」の4つの選択肢から適切なものを選択してください。
回答の正確性、自然さ、有用性、創造性などを総合的に判断することが重要です。
例えば、Assistant A(左)の回答がより具体的で実用的な場合は「Left is Better(左の勝ち)」を、両方とも同程度の品質なら「Tie」を選択します。
リーダーボードの見方とランキング活用術
総合ランキング(Overall)の読み方と意味
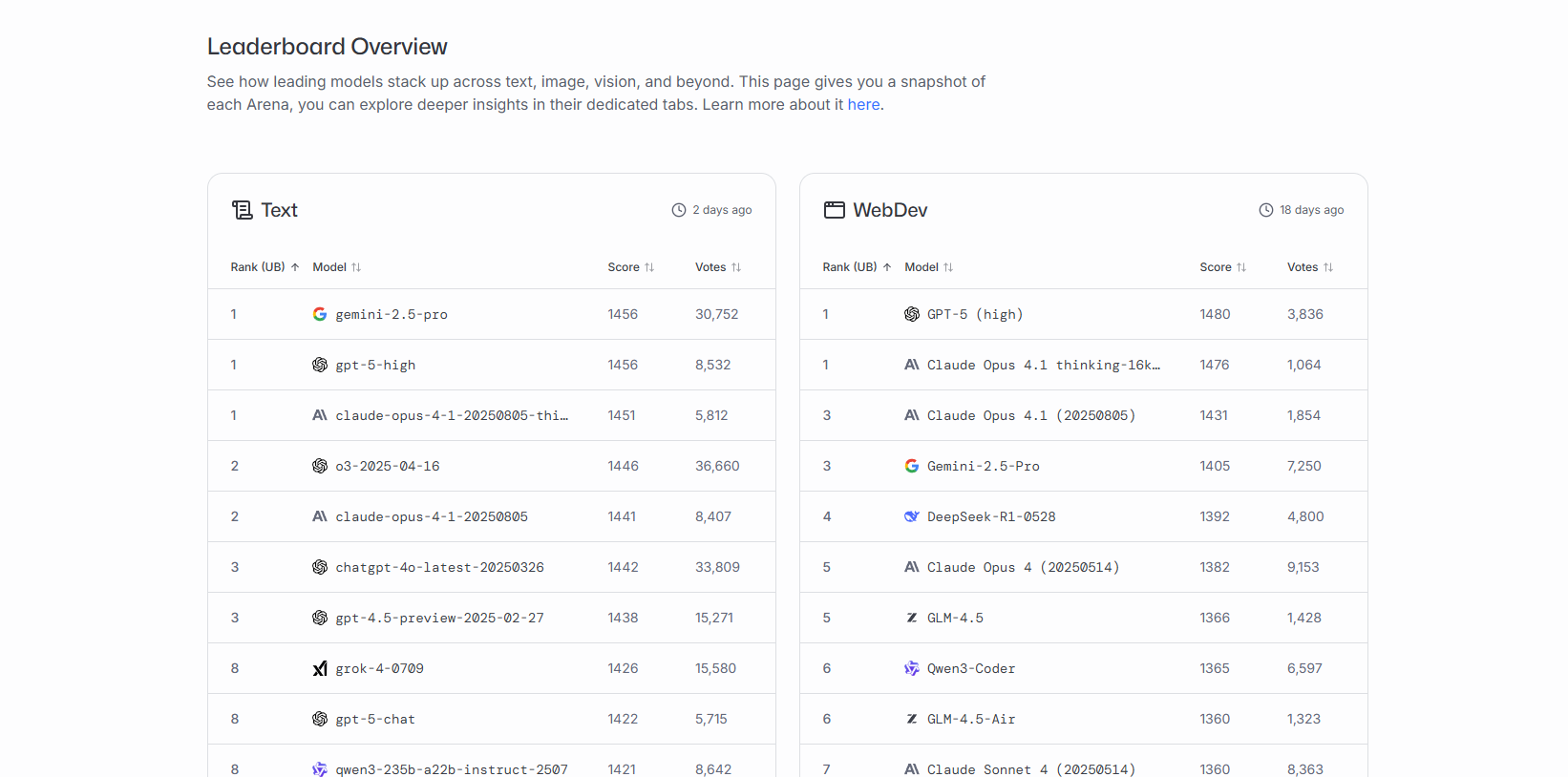
リーダーボードの総合ランキングは、全カテゴリーの評価を統合したAIモデルの総合力を示す最重要指標です。
Text、WebDev、Vision、Text-to-Image、Image Edit、Search、Text-to-Video、Image-toVideo、Copilot、など、様々なカテゴリ別にランキングが表示されています。
ランキング上位のモデルほど幅広いタスクで高い評価を獲得しており、汎用性に優れていることを意味します。
2025年8月時点では、OpenAIが2025年8月7日にリリースしたGPT-5が多くのカテゴリで上位を占めており、続いてGemini 2.5 Pro、Claude Opus 4、ChatGPT-4oなどが高い評価を獲得しています。
順位は投票率や勝率で順次継続的に更新されています。
カテゴリ別ランキング(Text・WebDev・Vision等)の解説
LM Arenaでは目的別に細分化されたカテゴリランキングを提供しており、特定用途での最適なモデル選択が可能です。
「Text」カテゴリは一般的な文章生成や対話能力、「WebDev」はHTML/CSS/JavaScriptなどのコーディング支援、「Vision」は画像認識や解析能力を評価しています。
「Search」では情報検索の精度、「Copilot」ではプログラミング補助機能、「Text-to-Image」では画像生成能力が測定されます。
各カテゴリで異なるモデルが上位にランクインしているため、用途に応じた適切な選択が重要になります。
| カテゴリ | 評価内容 | 主要な上位モデル例(2025年8月時点) |
|---|---|---|
| Text | 一般的な文章生成・対話 | GPT-5、ChatGPT-4o、GPT-4.5 |
| WebDev | HTML/CSS/JavaScript | Claude Opus 4、GPT-5 |
| Vision | 画像認識・解析 | GPT-5、ChatGPT-4o |
| Copilot | プログラミング補助 | Claude 3.5 Sonnet、Deepseek V2.5 |
| Text-to-Image | 画像生成 | imagen-3.0、GPT-image-1 |
ランキングの見方とAIモデルの判断
スコアは、各AIモデルの相対的な強さを数値化した評価指標です。
スコアが高いほど他のモデルとの対戦で勝率が高いことを示し、一般的に1400以上が高性能、1500以上が極めて優秀なレベルとされています。
例えば、1450のモデルが1400のモデルと対戦した場合、前者の勝率は約57%と予測されます。
スコア差が100点あると勝率は約64%まで上昇するため、100点以上の差があるモデル間では明確な性能差があると判断できます。
この数値を参考にすることで、具体的な性能差を定量的に把握することが可能です。
| Eloスコア範囲 | 性能レベル | 勝率の目安 |
|---|---|---|
| 1500以上 | 極めて優秀 | 上位モデル |
| 1400-1499 | 高性能 | 標準より優秀 |
| 1300-1399 | 標準的 | 平均的な性能 |
| 1300未満 | 改善が必要 | 下位モデル |
投票数(Votes)と信頼性の関係
各モデルの評価信頼性は利用回数によって大きく左右されるため、とうひょう数を確認することが重要です。
投票数が1000未満のモデルは統計的な信頼性が低く、一時的な変動でランキングが大きく変わる可能性があります。
一方、10000以上の投票を集めたモデルは安定した評価が得られており、実際の性能を正確に反映していると考えられます。
新しいモデルや知名度の低いモデルは投票数が少ない傾向にあるため、スコアだけでなく投票数も併せて確認してから判断することをお勧めします。
Arena Overviewでの最適なAIモデルの選び方
文章作成・ライティングに強いモデルの見つけ方
文章作成用途では「Text」カテゴリと「Creative Writing」の両方で高評価を得ているモデルを選択することが効果的です。
これらのカテゴリで上位にランクインするモデルは、論理的な構成力と創造的な表現力を兼ね備えており、ビジネス文書から創作物まで幅広く対応できます。
例えば、ブログ記事やマーケティングコピーの作成では、自然な文体と魅力的な表現が求められるため、Creative Writingスコアの高さが重要になります。
「Instruction Following」スコアも併せて確認することで、指定した文体や条件に正確に従うモデルを特定できます。
プログラミング・コーディング用途での選び方
コーディング支援では「WebDev」と「Copilot」カテゴリのランキングを重点的にチェックしましょう。
これらのカテゴリで高評価を受けるモデルは、構文の正確性だけでなく、実用的で保守しやすいコードを生成する能力に長けています。
特に複雑なアルゴリズムや大規模なプロジェクトでは、「Coding」カテゴリでの評価も重要な判断材料となります。
例えば、React開発やPython機械学習プロジェクトなど、特定の技術スタックを使用する場合は、該当分野での実績や評価コメントも参考にすることをお勧めします。
画像認識・ビジョンタスク向けモデルの特徴
画像関連タスクでは「Vision」カテゴリのランキングが最も重要な指標となります。
このカテゴリで上位のモデルは、画像内容の正確な認識、詳細な説明生成、オブジェクト検出などの能力に優れています。
医療画像解析やECサイトの商品画像管理など、専門性の高い用途では精度が特に重要になるため、投票数の多い安定したモデルを選択することが推奨されます。
また、マルチモーダル機能を持つモデルでは、画像と文章を組み合わせた複合的なタスクにも対応可能です。
複雑な指示・長文処理が得意なモデルの判断基準
高度な思考力や長文理解が必要なタスクでは、「Hard Prompts」と「Longer Query」カテゴリでの評価を重視してください。
これらの指標が高いモデルは、多段階の推論、複雑な条件設定、長文の要約や分析などに優れた能力を発揮します。
例えば、法的文書の分析や学術論文の要約、戦略的思考を要するビジネス課題などでは、これらの能力が不可欠です。
「Multi-Turn」スコアも併せて確認することで、継続的な対話を通じて段階的に問題を解決できるモデルを見つけることができます。
LM Arena活用時の注意点と評価の信頼性
投票バイアスと公平性に関する議論
LM Arenaの評価には、ユーザーの文化的背景や言語的偏見が影響する可能性があります。
英語圏のユーザーが多い場合、英語での応答品質を重視する傾向があり、他言語での性能が過小評価される恐れがあります。
また、技術系ユーザーの比率が高いため、プログラミング関連の評価は信頼性が高い一方、芸術や文学的な創作については評価の精度が劣る可能性があります。
これらのバイアスを理解した上で、自分の用途や言語環境に適した評価を重視することが重要です。
実際に、Cohere社などの研究者は、Meta・Googleなど大手企業による不透明な評価手法について疑問を呈しており、LM Arena運営チームは「事実誤認」として反論している状況もあります。
出典:Ledge.ai記事
ランキング変動の理由と最新情報の確認方法
LM Arenaのランキングは日々変動するため、定期的な確認が必要です。
新しいモデルの追加、既存モデルのアップデート、ユーザー投票の蓄積などがランキング変化の主な要因となります。
特に新モデルは初期の投票数が少ないため、大きな順位変動を示すことがあります。
最新の情報を把握するには、公式サイトの更新日時を確認し、週1回程度のペースでランキングをチェックすることをお勧めします。
また、各モデルの詳細ページでは投票トレンドのグラフも確認できます。
2025年8月には、OpenAIのGPT-5リリースにより大きなランキング変動が発生しました。
出典:LM Arena News – Leaderboard Changelog
企業による不正操作疑惑と対策
一部の企業が複数の未公開モデルを投入し、最良の結果のみを公表する「チェリーピッキング」の疑惑が指摘されています。
2025年4月の調査によると、Meta社はLlama 4を公開する前の1か月間で、少なくとも27個の非公開モデルをテストしていたことが判明しました。
出典:日経クロステック記事
このような操作を防ぐため、LM Arena運営チームは投票パターンの異常検知や、同一IPからの大量投票の監視を実施しています。
ユーザー側でも、急激にランキング上昇したモデルについては投票数やスコア推移を慎重に確認し、一時的なブーストではなく持続的な高評価かを見極めることが重要です。
実際にLM Arenaを使ってみよう【実践編】
効果的なプロンプト(質問)の作り方
LM Arenaで有意義な比較を行うには、明確で具体的なプロンプトの作成が重要です。
「○○について教えて」のような曖昧な質問ではなく、「マーケティング予算100万円で新商品を宣伝する場合の戦略を3つ、具体的な実施方法と期待効果を含めて提案してください」のように詳細な条件を指定しましょう。
また、あなたが実際に使用する場面を想定したプロンプトを用いることで、実用性の高い評価を行うことができます。
複数の観点から評価するため、創造性、論理性、実用性など異なる要素を求める様々なプロンプトを試すことをお勧めします。
継続的にランキングをチェックするコツ
LM Arenaを効果的に活用するには、定期的なモニタリング習慣の確立が欠かせません。
週1回程度の頻度で総合ランキングと関心のあるカテゴリをチェックし、新規参入モデルや大幅な順位変動を把握しましょう。
ブラウザのブックマーク機能を活用し、特定のカテゴリページを保存しておくと効率的です。
また、自分が評価に参加したモデルの追跡も重要で、その後の順位変動や評価トレンドを観察することで、AI業界の動向を肌で感じることができ、将来のテクノロジー選択に活かすことができます。
参考・引用サイト
- LM Arena公式サイト
- LM Arena公式リーダーボード
- LM Arena News – Leaderboard Changelog
- OpenAI GPT-5発表
- Philipp Tarohl Hiltl氏のブログ記事「LM Arenaで最新AIモデルの人気ランキングと実力を徹底比較!」
- ぱやなーく氏のnote記事「LM Arena発!あなたに合うAI発見術|ぱやなーく式・AI活用術」
- あいなトイ氏のnote記事「LM Arenaを使ってわかる「AIモデルの実力」とは」
- AI CBAgames.jp「今人気のAIが一目でわかる!無料で試せるAIランキングサイト「LM Arena」と「Artificial Analysis」の使い方を徹底解説!」
- AIDB記事「あらゆるLLMを「使い心地」基準でバトルさせる便利なプラットフォーム『Chatbot Arena』」
- Ledge.ai記事「LLMの評価ランキング「Chatbot Arena」にMeta・Googleなど大手優遇の疑惑」
- nobita氏のブログ記事「LM Arenaとは?AIモデルの真の力をユーザーが評価する最前線」
- 日経クロステック記事「影響力が強いAI性能ランキング「Chatbot Arena」に疑義」
- Zenn記事「【速報】GPT-5がLM Arenaで圧倒的首位!全カテゴリで他モデルを圧倒」

