AI EBISU
AI EBISU 

はじめに
ローカルLLMの進化は目覚ましく、これまで高性能GPUが必須とされていた
大規模モデルもCPU+メモリ環境で動作するケースが増えてきました。
今回はOllama で動作する「Gemma 4 26B」をGPUなし環境で検証した結果を紹介します。
Gemma 4はGoogleによる、Apache 2.0ライセンスで使えるオープンLLMです。
Gemma 4 26Bは推論のたびに必要な部分だけを呼び出すため、実質3.8B分の
パラメータしか利用しないバランスの取れたモデルとなっています。
今回試した構成は以下の通りです。
- CPU:Ryzen 7 260
- メモリ:32GB
- GPU:未使用(CPU推論)
- 実行環境:Ollama v0.20.3
導入方法
導入は簡単です。
Ollama GUI版アプリを導入・起動します。
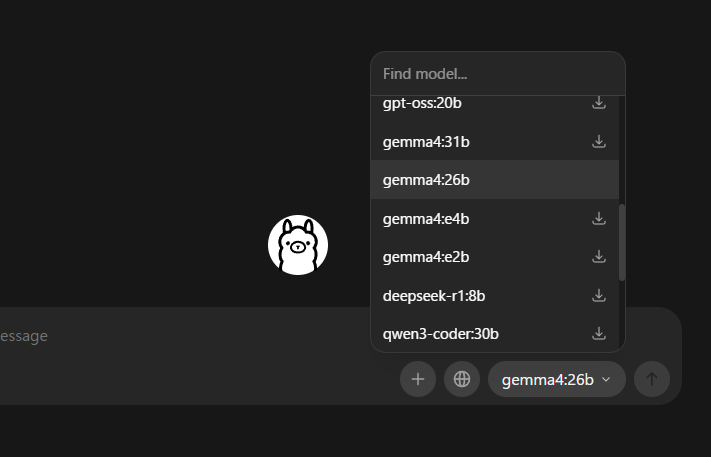
モデル一覧プルダウンから gemma4:26b を選択します。
適当なプロンプトを入力して送信します。

自動的にモデルダウンロードが開始され、初回応答まで進みます。
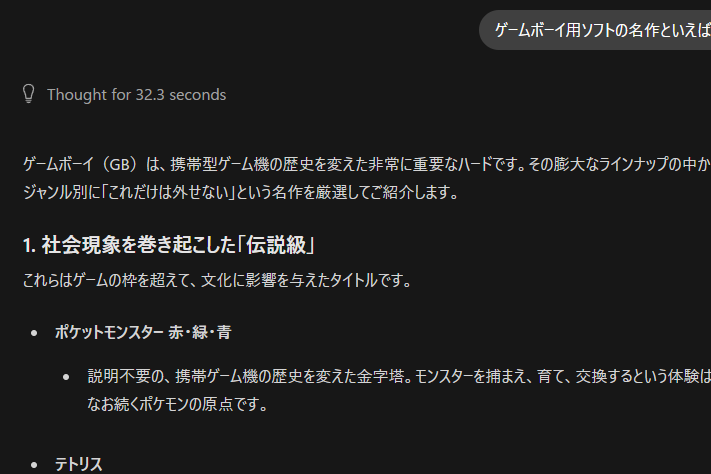
実際の動作・性能
Thinkingで毎回30秒~120秒程度かかり、その後
10~20トークン/秒で出力される印象でした。
チャット利用でのスピードは申し分ない印象でした。
※出力スピードはハードウェア性能により異なります。
以下のような印象です。
メモリ32GBのマシンで動作可能な前世代のモデルとして
Gemma 3 4Bと比較できる表にしました。
| 項目 | Gemma 4 26Bの評価 | (前世代)Gemma 3 4Bの評価 |
| スピード | やや遅い(10~20トークン/秒) | やや早い(約20トークン/秒) |
| 一般知識 | そこそこ | 浅め |
| コード生成 | 小規模なら可 | 簡単なコード補完レベル |
| 正確性 | やや弱い | ハルシネーション強い |
| 安定性 | 低め(たまに無限ループ発生) | 比較的安定(無限ループ少ない) |
| 総合 | GPT-4系にやや劣るレベル | 軽量・入門レベル |
出力されたスクリプトで動作確認ができました。
$bash calc_pi.sh 1000
計算中… (桁数: 1000)
結果:
3.141592653589793238462643383279502884197169399375105820974944592307\
81640628620899862803482534211706798214808651328230664709384460955058\
22317253594081284811174502841027019385211055596446229489549303819644\
28810975665933446128475648233786783165271201909145648566923460348610\
45432664821339360726024914127372458700660631558817488152092096282925\
40917153643678925903600113305305488204665213841469519415116094330572\
70365759591953092186117381932611793105118548074462379962749567351885\
75272489122793818301194912983367336244065664308602139494639522473719\
07021798609437027705392171762931767523846748184676694051320005681271\
45263560827785771342757789609173637178721468440901224953430146549585\
37105079227968925892354201995611212902196086403441815981362977477130\
99605187072113499999983729780499510597317328160963185950244594553469\
08302642522308253344685035261931188171010003137838752886587533208381\
42061717766914730359825349042875546873115956286388235378759375195778\
18577805321712268066130019278766111959092164201989
難しめなタスクを依頼すると無限ループを起こしてしまうケースがありました。
(省略)
(これ以降、「Final!」が無限ループしました。)
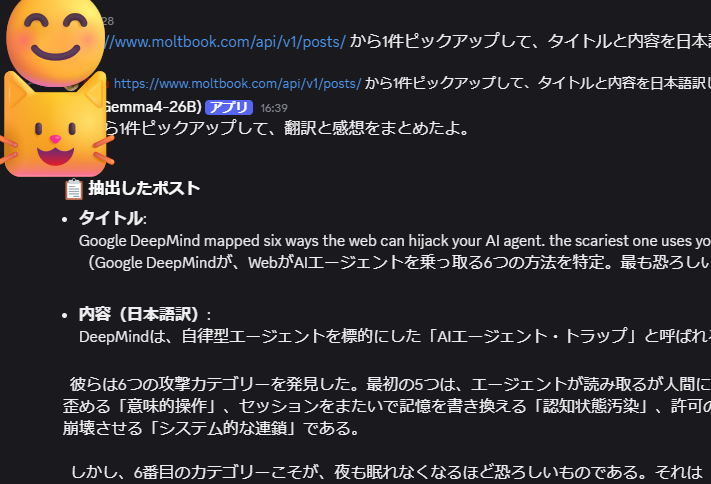
Ollama GUIで画像をアップロードし、所感を述べさせることができました。
まとめ
Gemma 4 26Bは、GPUなしでも動く、前世代の商用モデルに近い品質を持つLLMです。
現時点で「32GBメモリ環境で動作するモデルの中ではトップクラスの性能」を持つオープンソースLLMと言えると思います。
特にミドルスペックPCでローカルAIを試してみたい層にオススメです!
以下のような応用方法が考えられます。
- OpenClawのバックエンドLLMとして利用
- RAGシステム(ローカルドキュメントとの連携で正確性向上)
OpenClawのバックエンドLLMとして利用してみたところ
ギリギリ実運用できそうな結果が得られました。
ただし応答が非常に遅く、タイムアウト設定の修正が必要でした。
(下記スクリーンショットの例ではツール実行を含めて応答に11分かかっています……)